はじめに
前回k-meansでBICを使うのはいいんじゃないか?という記事を書いたと思います。
この記事に関していくつかの指摘をいただいたので、それならばk-means専用にカスタマイズした情報量を考えてみようという発想に至りました。ということで、今回はk-means専用のKIC(K-means Information Criterion)の考案に関して記事を書いていきたいと思います。なにぶん初学者のため、色々間違っている部分が出てくるかもしれませんがご了承ください。
k-meansの特殊性と従来の課題
まず、K-meansの持つ特殊性について整理していきましょう。k-meansは以下の目的関数を最小化します:
わかりやすく説明すると、この式は「各データ点が、所属するクラスターの中心からどれだけ離れているか」の総和を表しています。つまり、全てのデータ点について、それぞれが属するクラスターの中心までの距離を二乗して足し合わせた値です。k-meansアルゴリズムは、この値をできるだけ小さくするように、クラスター中心の位置とデータ点の所属クラスターを決定していきます。
k-meansの特殊性として、以下の三点が挙げられます:
これらの特性により、従来のBICなどの情報量規準をそのまま適用することに理論的な課題があることをXにてご指摘いただきました。
KICの提案
これらの特性を考慮し、以下のような新しい情報量規準KICを提案します:
この式は、クラスター中心間の距離が近すぎる場合にペナルティを課すものです。βはスケールパラメータで、距離の評価の厳しさを調整します。
概念的に説明すると、KICはデータへの当てはまりの良さとモデルの複雑さのバランスを取ろうとしています。RSSによってクラスタリングがデータにどれだけフィットしているかを測り、最初のペナルティ項でクラスター中心を表現するのに必要なパラメータの数を考慮します。次のペナルティ項ではデータ点をクラスターに割り当てる際の複雑さを評価し、最後のペナルティ項でクラスターが適度に離れているかをチェックします。
KICの理論的性質に関する考察
まず、KICの一致性を示すために必要な仮定を導入し、その後で詳細な証明を展開していきます。
理論的な仮定
漸近的性質を議論するために、以下の仮定を置きます:
直感的に説明すると、この仮定はデータ点の数に対してクラスター数が急激に増えすぎないようにする制約です。例えば、データ点が1000個あるとき、クラスター数は最大でも約10個程度に抑えられるべきということを示唆しています。これは現実のクラスタリング問題において自然な仮定といえます。
この仮定を概念的に説明すると、クラスター同士が「適度に離れている」ことを要求しています。ただし、データ数が増えても、必要な分離距離はごくゆっくりとしか大きくならない(二重対数のオーダー)という、実用的な条件となっています。
この仮定は、極端に小さなクラスターが作られることを防ぐための条件です。たとえば、データ点が1000個で10個のクラスターを作る場合、各クラスターは少なくとも10個程度のデータ点を含むべきということを示しています。
漸近的性質の証明
これらの仮定の下で、KICの一致性を証明していきます。証明は三段階で行います。
第一段階:バイアス項の評価
まず、KICの期待値の差分を詳細に評価していきます。
KICの定義から、差分は以下のように展開されます:
第二段階:分散の評価
KICの分散を評価するために、まずRSSの分散を考えます:
ペナルティ項の分散は決定的な項であるため、KIC全体の分散も同じオーダーとなります:
第三段階:一致性の証明
一致性の証明のために、まず以下の確率不等式を考えます:
この確率は、Boole-Cantelli型の不等式を用いて上から評価できます:
Chebyshevの不等式を適用すると:
が証明されます。
比較検証してみる
最初に結論を言うと、理論の証明のために置いた3つの仮定を厳密に守ったKICの算出によるクラスタ数の決定は上手くいかなかった。ただ仮定をフル無視して算出したKICはどの指標よりも結果的にうまく機能した。これは単純なサンプルデータによる結果であるため、もしかしたら本当は別指標のほうが優れていたというのはあるのかもしれない。
結果だけ以下に載せていく。
真のクラスタ数8
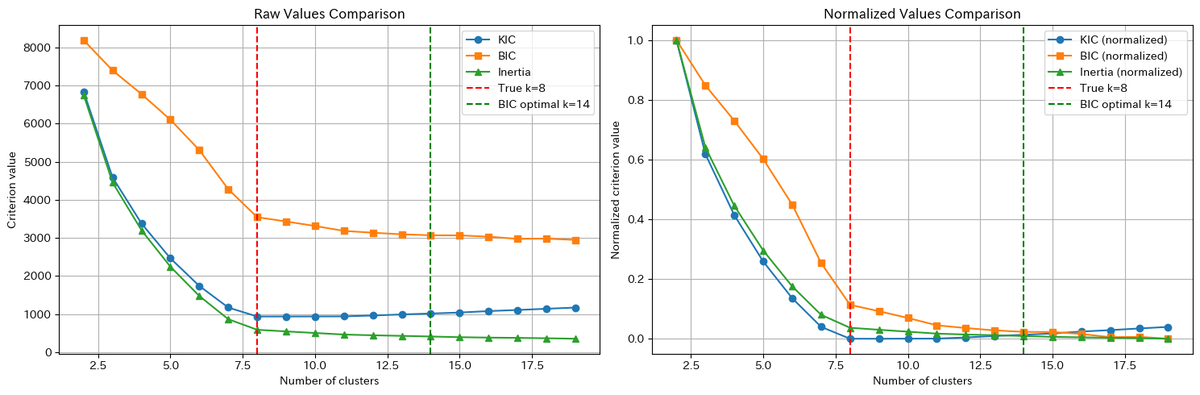 データをもっと複雑にし、真のクラスタ数5にしてみる
データをもっと複雑にし、真のクラスタ数5にしてみる
 人為的に生成したサンプルデータでの検証はこの辺が限界かなと思いますが、今のところKICが一番よさげな挙動を見せていると思います。
人為的に生成したサンプルデータでの検証はこの辺が限界かなと思いますが、今のところKICが一番よさげな挙動を見せていると思います。
因みに今回のKICはユークリッド距離を前提に作っているので、コサイン類似度などでは機能しません。コサイン類似度でやる場合はまた新しく考えるか、エルボー法が一番よさそうな結果を出しました。BICは以前の記事で書いた理論的にユークリッド距離よりももっと深刻な問題を抱えているので論外ですね...
最後に
BICの代わりにもといい情報量規準をと思い机上の空論で作ってみましたが、机上の理論と実際の動作が上手くかみ合わなかったですね...まあ素人が思いつくことはすでにほかの人がやっているとはよく言ったもので、難しいものではありますねw
コサイン類似度に最適化した情報量規準も考えられないかなと空想しましたが、難しそうですね...個人的にクラスタリングでコサイン類似度でのクラスタリングを個人的によく使うので、あったらうれしいなとか思っています。
コサイン類似度でも万能に使えるでいうと、やはりエルボー法しか挙がってこないのは何とも言えませんね。やる気と妄想力が最高潮になった時があったら、コサイン類似度に最適化した情報量規準なるものを作ってみたいなとは思います。
意外とエルボー法強いな...と感じた今日この頃でした。
最後までお読みいただきありがとうございました。